Most Coding Agents Should Be Skills
I keep seeing AI coding setups described like a spec sheet.
50 agents.
60 agents.
100 agents.
One for React. One for tests. One for docs. One for SEO. One for APIs. One for migrations. One for releases. One for every job title that could plausibly appear in a software team.
It sounds impressive at first.
When I hear it now, I usually think something else: routing problem.
Most of those "agents" are probably skills.
That is not an anti-agent argument. Agents are useful. Subagents are useful. Agent teams can be useful. The issue is classification. A lot of people are turning reusable instructions, checklists, style guides, examples, and review rubrics into separate workers because "agent" feels more advanced than "skill."
That is how you get a complex system without getting a better one.
The Simple Split
Here is the mental model I would use:
A skill teaches an agent how to do something.
An agent gives work to a separate worker.
That difference sounds small, but it changes the architecture.
A skill is the right place for reusable expertise: a checklist, a procedure, a style guide, a workflow, a reference document, a set of examples, or a script-backed method the model should know how to apply.
An agent is the right place for an execution boundary: separate context, separate permissions, parallel work, a different model or tool budget, long-running ownership, or a worker that should return a summary without flooding the main thread.
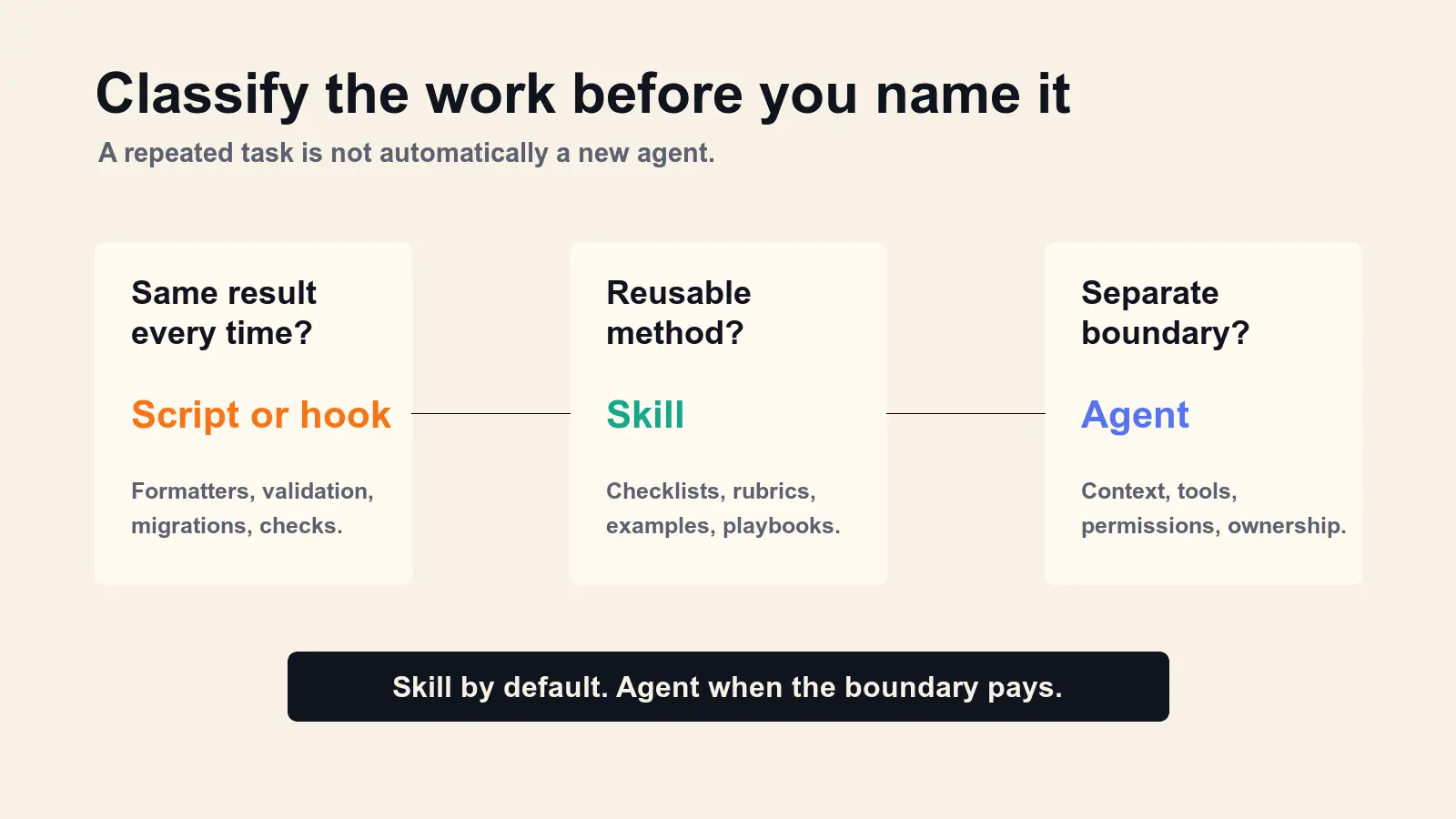
If the task just needs better instructions, make it a skill.
If the task needs its own room, make it an agent.
The Tools Are Already Telling Us This
The public docs for the major coding harnesses are pretty clear on this.
Claude Code's extension overview says skills add reusable knowledge and workflows, while subagents run their own loops in isolated context and return summaries. The same page gives a useful progression: when you keep typing the same prompt or pasting the same playbook, capture it as a skill. When a side task floods the conversation, route it through a subagent.
Codex points the same way. Codex skills are the authoring format for reusable workflows. They use progressive disclosure: Codex sees the skill name, description, and path first, then loads the full SKILL.md only when the skill is relevant. Codex subagents, on the other hand, are for specialized parallel work and cost more tokens because each subagent does its own model and tool work.
OpenCode has a similar split. It has a small built-in set of agents, then skills that are discovered from project or global folders and loaded on demand.
Across all three, the pattern is not "make every repeatable thing an agent."
The pattern is: keep a small number of real workers, then give those workers reusable skills.
Why 80 Agents Gets Fragile
Every agent you add creates a routing decision.
Which agent owns this task?
What if two agents match?
What if the planner sends work to the wrong one?
What if the docs agent needs the API convention that only the API agent knows?
What if the review agent and the test agent disagree because they were given slightly different prompts?
At small scale, this feels manageable. At 50 or 80 named agents, the system starts to behave like an org chart made of prompts. The hard problem becomes deciding who should do the work, not doing the work.
Skills avoid some of that failure mode because they are not separate workers. They are reusable capability modules that the current agent, or a real subagent, can load when needed.
That means your test strategy can be used by the implementer and the reviewer. Your docs style can be used by the main agent and a documentation subagent. Your API conventions can travel with the work instead of living inside one persona.
The skill becomes portable expertise.
The agent remains an execution boundary.
Use A Skill By Default
I would start with this rule:
Use a skill by default. Promote to an agent only when the boundary pays for itself.
That means a workflow is probably a skill when it looks like this:
| Signal | Better artifact |
|---|---|
| I keep pasting the same checklist | Skill |
| I need a repeatable review method | Skill |
| I need reusable domain knowledge | Skill |
| I need examples, templates, or scripts | Skill |
| I need a style guide the agent can apply sometimes | Skill |
A workflow may deserve an agent when it looks like this:
| Signal | Better artifact |
|---|---|
| The work would flood the main context | Subagent |
| The worker needs different tool permissions | Subagent |
| The task should run in parallel | Subagent |
| The work needs a different model or cost profile | Agent or subagent |
| The worker has long-running ownership | Agent |
| Multiple workers need to challenge each other | Agent team |
There is also a third bucket people forget: deterministic work.
If the step should happen the same way every time, it may not belong in a skill or an agent. It may belong in a script or hook. Formatting, validation, migrations, generated files, security blocks, and build steps should usually be code.
Do not spend model judgment on work a program can enforce.
What A Mature Setup Looks Like
For a serious coding harness, I would expect the number of true agents to stay small.
Maybe there is an explorer that reads broadly and returns findings.
Maybe there is a worker that implements.
Maybe there is a reviewer that checks the diff.
Maybe there is a security or QA reviewer with restricted tools.
Maybe there is a researcher for source-heavy work.
Then I would expect a much richer skills layer:
agents/
explorer.md
implementer.md
reviewer.md
security-reviewer.md
skills/
api-conventions/
component-patterns/
database-migration-checklist/
docs-style/
pr-review-rubric/
release-notes/
test-plan/
ux-copy-rules/
The agents own execution boundaries.
The skills carry reusable expertise.
That separation makes the setup easier to maintain when Codex, Claude Code, OpenCode, or the model underneath them changes. If the provider improves subagent orchestration, your real agents get better. If the provider improves skill loading, your skill library gets better. You are not stuck maintaining 80 fragile persona prompts that overlap with the platform.
The Fair Exception
There are real cases for larger agent systems.
Production agent products may need separate runtime roles. Research systems may compare competing hypotheses. Evaluation harnesses may use agents to judge, attack, or verify one another. Large background automation systems may need queues, permissions, logs, and ownership boundaries. Agent teams can make sense when independent communication is part of the work.
So the point is not "never make agents."
The point is: do not use an agent when a skill would give you the same capability with less orchestration.
If your setup has 80 agents, I would ask a boring question before I admire it:
How many of those are actually separate workers, and how many are just reusable instructions with job titles?
That question usually reveals the architecture.
The Practical Takeaway
Stop counting agents.
Count clean boundaries.
An agent should exist because the work needs isolation, permissions, parallelism, model routing, memory, or independent ownership.
A skill should exist because the work needs a reusable method.
A script or hook should exist because the work needs enforcement.
The strongest AI coding setups will not be the ones with the longest agent roster. They will be the ones where every worker has a reason to exist, and every repeatable method has a clear place to live.
Most teams do not need more agents.
They need better skills.
Sources: Claude Code extension overview, Claude Code skills docs, Claude Code subagents docs, OpenAI Codex skills docs, OpenAI Codex subagents docs, OpenCode agents docs, OpenCode skills docs, Configuring Agentic AI Coding Tools: An Exploratory Study, and Agent Skills: A Data-Driven Analysis of Claude Skills.
Tagged